브라우저는 HTML를 어떻게 파싱할까?
브라우저의 렌더링 과정에서 빼놓을 수 없는 부분이 HTML 파싱입니다. 오늘은 HTML 파싱에 어떤 과정들이 필요한지 차근차근 알아보도록 하겠습니다.
설명에 앞서 이해를 도울 수 있는 그림을 준비했습니다.
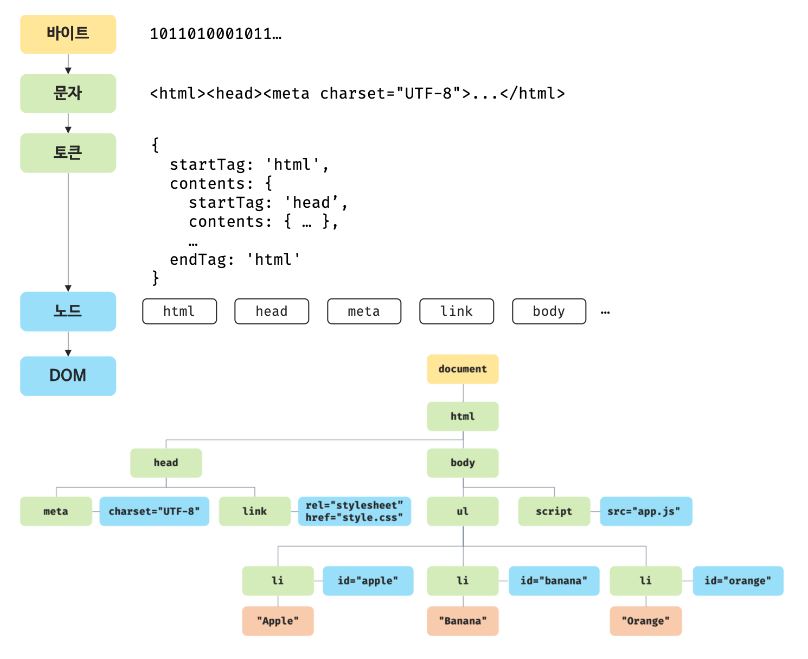
사용자가 페이지에 접속했을 때 브라우저는 서버에 HTML 파일을 요청합니다. 이때 서버는 메모리에 바이트 단위로 저장된 HTML 파일을 응답하게 됩니다. 10110100... 같은 형태로 보내게 되는 것이죠.
브라우저의 HTML 파서는 이 바이트 형태의 문서를 문자열로 변환합니다. 이때 response header에 담긴 content-type을 참고합니다. 예를 들어 content-type: text/html; charset=utf-8라고 되어있다면 utf-8 방식으로 인코딩을 하는 것이죠. content-type에 담긴 값은 meta 태그의 charset 어트리뷰트 값과 같습니다.
<meta charset="UTF-8">
이후 문자열로 변환된 HTML 문서를 읽어들여 문법적 의미를 갖는 코드의 최소 단위인 토큰들로 분해합니다.
{
startTag: 'html',
contents: {
startTag: 'head',
contents: {...},
...
endTag: 'html'
이제 DOM 트리를 구축할 차례입니다. 브라우저는 토큰들을 읽어나가면서 태그별로 노드 객체를 생성하고 중첩 관계가 있다면 부모-자식 관계를 설정합니다.
<html>
<body>
<div class="container">
Hello World
</div>
</body>
</html>
예를 들어 이런 문서가 있다면 아래와 같은 DOM 트리가 생성되는 것이죠.
[문서 노드 객체] document
└─ [요소 노드 객체] <html>
└─ [요소 노드 객체] <body>
└─ [요소 노드 객체] <div>
└─ [텍스트 노드 객체] "Hello World"
└─ [어트리뷰트 노드 객체] class="container"
여기서 문서 노드라는 단어가 낯설 수 있을 것 같습니다. 문서 노드 객체는 DOM 트리의 최상위에 존재하는 루트 노드로서 document 객체를 가리킵니다. document.getElementById 같은 메서드를 사용해본 경험이 있을텐데요. 문서 노드 객체는 DOM 트리의 노드들에 접근하기 위한 진입점 역할을 합니다.
// DOM 조작 예시
document.createElement()
document.querySelector()
element.appendChild()
element.setAttribute()
DOM은 노드 객체의 종류에 따라 필요한 기능을 프로퍼티와 메서드의 집합인 DOM API로 제공합니다. 이를 통해 HTML의 구조나 내용 또는 스타일 등을 동적으로 조작할 수 있습니다.
이상으로 브라우저의 HTML 파싱 과정을 알아보았습니다. 이 과정을 이해하면 브라우저가 페이지를 어떻게 렌더링하고, 우리가 작성한 HTML이 어떻게 DOM 트리로 변환되는지 명확히 알 수 있습니다. 여기까지 읽어주셔서 감사합니다 :)
(위 내용은 모던 자바스크립트 deep dive 도서를 참고하여 작성하였습니다)